
こんにちは。「画像の文字をテキストにしたい」と感じたことは多いのではないでしょうか?ネットで文字をコピペしようと思ったら画像でコピペ出来なかった。という場面は結構あります。またで本や書類を電子化する場合などもテキスト化されていた方が都合がよい場合が多いです。アマゾンのキンドル書籍などの電子書籍もテキストデータが入っているので文章の単語をコピペして検索できたりします。このような画像からテキスト認識して抽出する技術をOCR(Optical Character Recognition/Reader)といいます。今回は【python】を使用し画像から文字を抽出する方法をご説明します。
TesseractをPCにインストール
いつもはすかさずコードを記載していますが、今回は準備が必要です。pythonでOCRをする場合、外部のソフトから読み込んで実行します。今回は「Tesseract」というソフトから実行していきます。
こずはこちらからhttps://github.com/UB-Mannheim/tesseract/wiki「Tesseract」をダウンロードします。 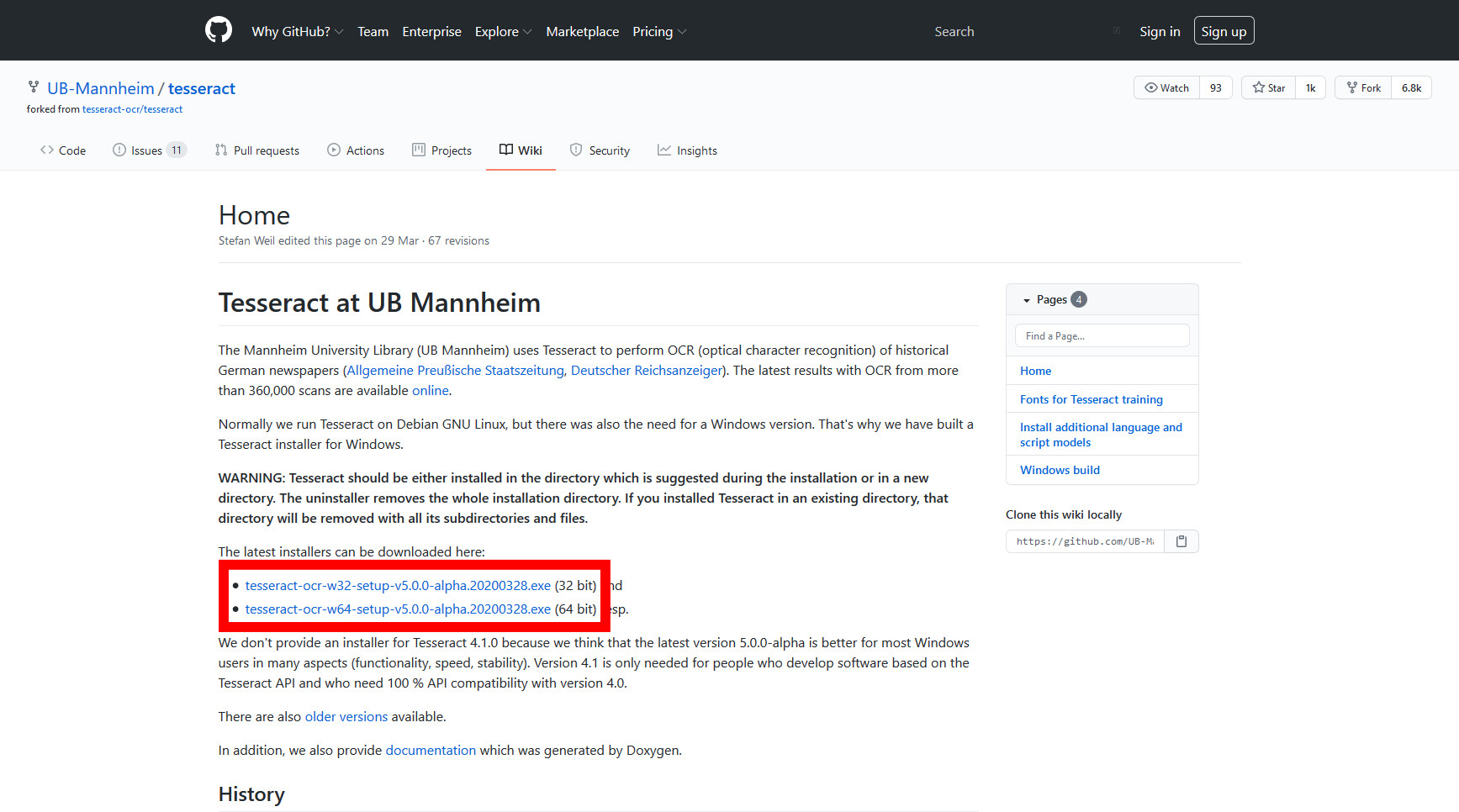
ご使用の環境に合わせて、“32ibt”か“64bit”を選択してください。
ダウンロードが終わればインストールしましょう
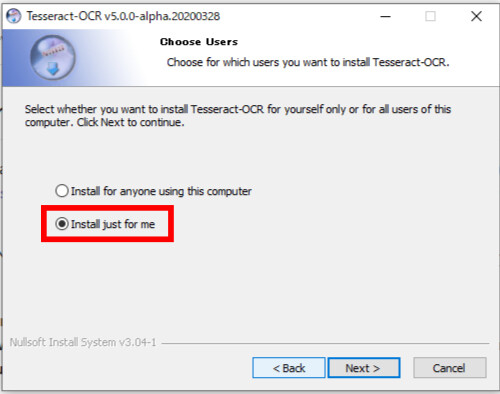
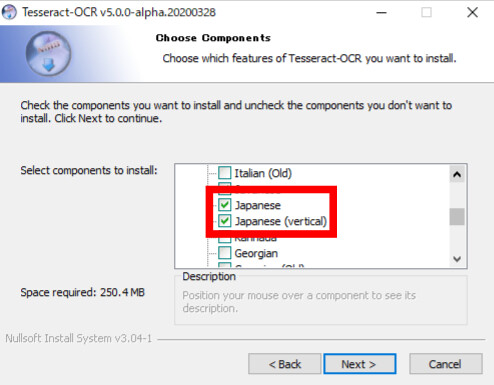
今回は日本語のファイルをを追加してインストールするので「Install just for me」にチェックして次へいってください。
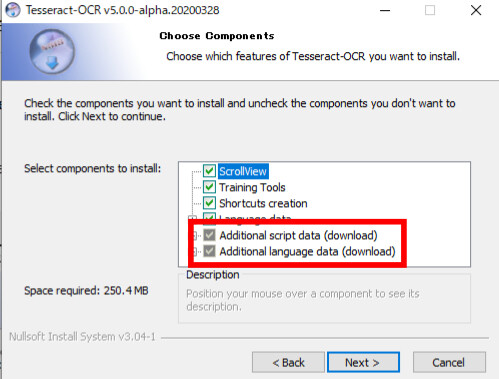
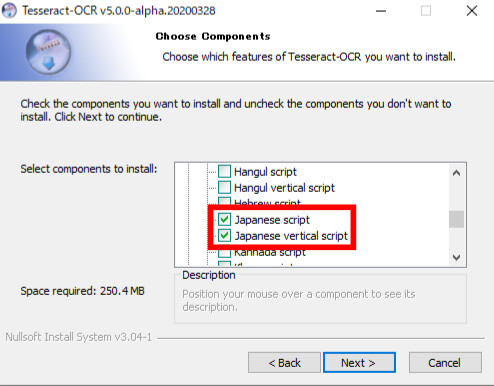
「Additional script data(download)」から「Japanese script」と「Japanese vertical script」、「 Additional language data(download)」から「Japanese」「Japanese(vertical)」をチェックして次へ行き、インストールを完了してください。
これで「Tesseract」のインストールは完了です。次からはpythonのコードになります。
OCRで画像から文字を抽出するコード
from PIL import Image
import pyocr
import os
path = 'C:/Users/[ウィンドウズのユーザー名]/AppData/Local/Tesseract-OCR'
os.environ['PATH'] = os.environ['PATH'] + path
tools = pyocr.get_available_tools()
tool = tools[0]
img = Image.open("画像ファイルのパス")
builder = pyocr.builders.TextBuilder(tesseract_layout=6)
text = tool.image_to_string(img, lang="jpn", builder=builder)
text = text.replace(' ', '')
print(text)
以上がコードになります。今回も非常に短いコードで実現しました。
コードの解説
ではコードの内容を詳しく見ていきましょう。
1から3行目でモジュールをインポートしています。今回は「PIL」「pyocr」「os」をインポートしています。「PIL」「pyocr」モジュールはそれぞれインストールが必要ですので入っていない方はインストールしてください。「PIL」は画像を読み込むモジュールで、「pyocr」は「Tesseract」などの外部OCRソフトを実行させるモジュールです
pip install Pillow
※「Pillow」は「PIL」のモジュール名です、「Pillow」をインストールして「PIL」という名前で読み込みます。
pip install pyocr
5.6行目で「Tesseract」の実行ファイルがあるディレクトリ(フォルダ)を指定しています。windows10の場合は「C:/Users/[ウィンドウズのユーザー名]/AppData/Local/Tesseract-OCR」になります。その他のOSの場合は「Tesseract」がインストールされたディレクトリ(フォルダ)を指定してください。※実行ファイルのパスではないので注意してください。
8行目で画像ファイルのパスを指定してください。「jpg」でも「png」でも大丈夫です。
10行目の「tesseract_layout=」でOCRの読み取りの方針を設定しています。これを適切に設定するとしないでは、精度が全く違ってきます。今回は6に設定しました。
11行目で実行しています。「lang=」には読みたい言語を入れます。今回は日本語で書かれた画像を処理しますので「jpn」にしています。
13行目は結果の出力の際に文字の間に半角スペースが入っていたので、読みやすいように半角スペースを除去しするコードです。こちらはなくても大丈夫です。
“tesseract_layout”について
処理の精度は「tesseract_layout」によって全く変わってきますので、こちらを適切に設定することが大切です。設定できる数字の意味は下記のとおりです。
- 0 = Orientation and script detection (OSD) only.
- 1 = Automatic page segmentation with OSD.
- 2 = Automatic page segmentation, but no OSD, or OCR
- 3 = Fully automatic page segmentation, but no OSD. (Default)
- 4 = Assume a single column of text of variable sizes.
- 5 = Assume a single uniform block of vertically aligned text.
- 6 = Assume a single uniform block of text.
- 7 = Treat the image as a single text line.
- 8 = Treat the image as a single word.
- 9 = Treat the image as a single word in a circle.
- 10 = Treat the image as a single character.
翻訳してみました。
- 0 =方向およびスクリプト検出(OSD)のみ。
- 1 = OSDによる自動ページセグメンテーション。
- 2 =自動ページセグメンテーション、ただしOSDまたはOCRなし
- 3 =完全自動のページセグメンテーション。ただし、OSDはありません。 (デフォルト)
- 4 =可変サイズのテキストの単一列を想定します。
- 5 =垂直に配置されたテキストの単一の均一なブロックを想定します。
- 6 =単一の均一なテキストブロックを想定します。
- 7 =画像を単一のテキスト行として扱います。
- 8 =画像を1つの単語として扱います。
- 9 =画像を円の中の1つの単語として扱います。
- 10 =画像を単一の文字として扱います。
以上のとおりです。画像に合わせた、設定はしましょう。
OCRの実行結果
では上記のコードでどれくらいの精度なのか確認していきましょう。今回は弊社の記事の【クリック率No.1】FAQの構造化データを徹底解説の冒頭部分をいくつかのパターンで実行してみます。
プレーンテキストの場合

こちらは記事の冒頭部分のプレーンテキストを画像化したものです。OCRにとっては一番難易度の低い画像になります。
実行結果
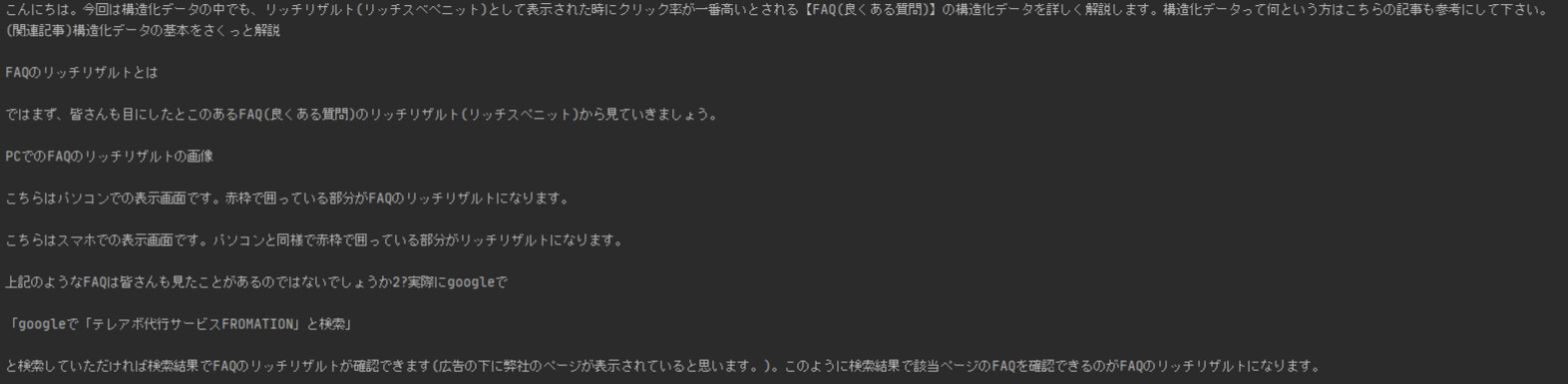
こちらが実行結果です。ほぼ完璧ですねかなりの精度です。元データがこれくらいきれいなデータならかなりの精度でテキスト化が可能です。
スクリーンショットの場合

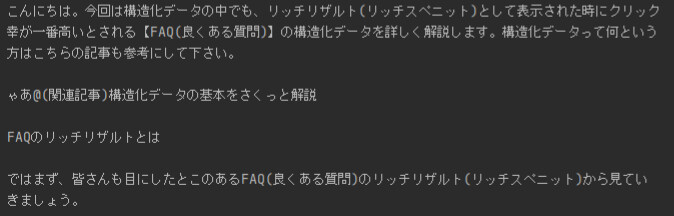
こちらは該当ページのスクリーンショットです。この画像ではどうなるでしょうか。
実行結果
一部のアンダーラインが消えていたり、間違いはあるものの精度は悪くないです。
スキャナで読み込んだ画像

次は該当ページを印刷しスキャナで白黒で取り込んだ画像です。認字しやすいように画像をトリミングしています。本や書類などのデジタル化をおこなう場合はこの方法を取ることになると思います。
実行結果
こちらも画像の部分が文字として認識されていますが、全体的には満足のいく結果となっています。
スマホのカメラで撮影した画像
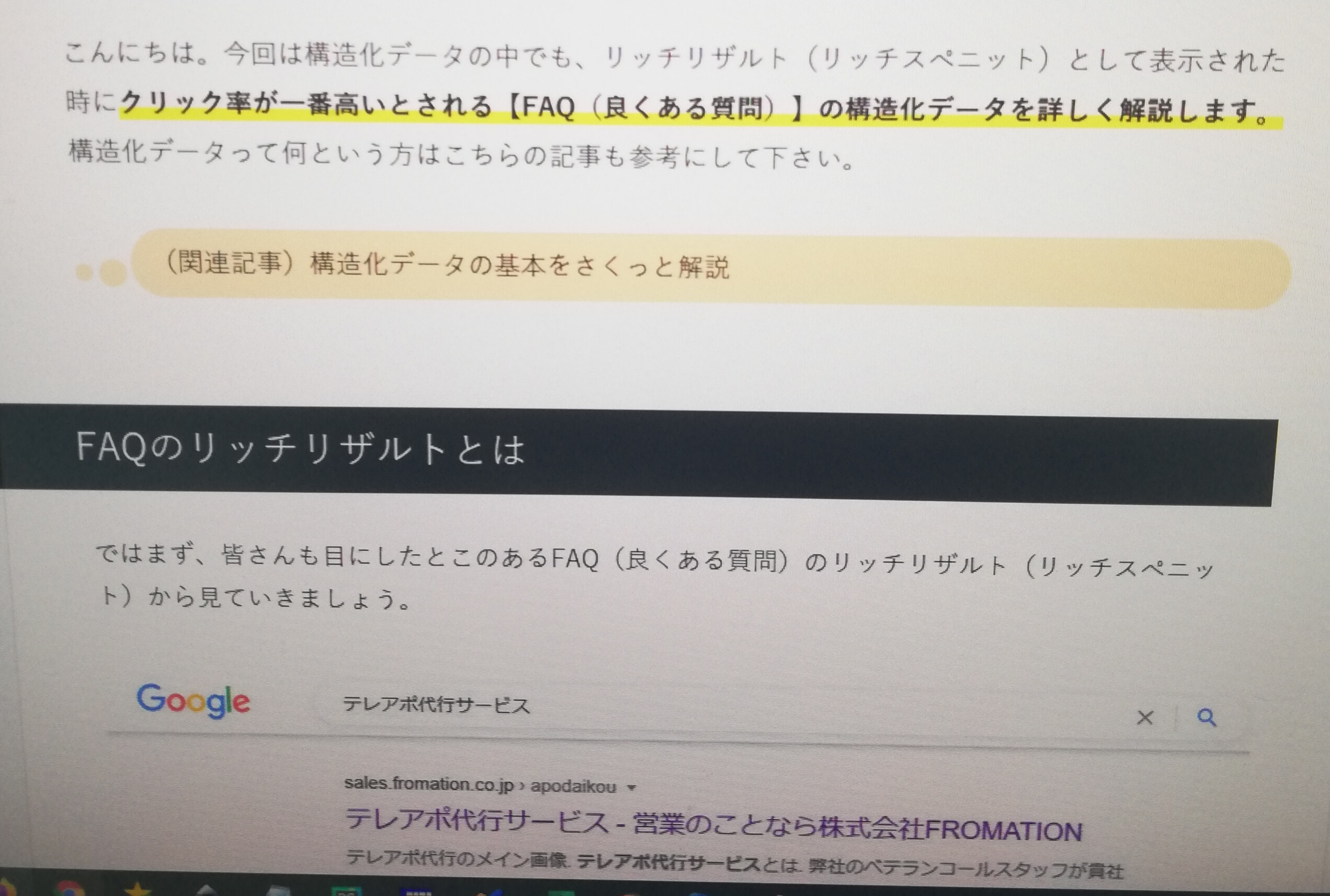
最後は該当ページをスマホのカメラで撮影した画像です。
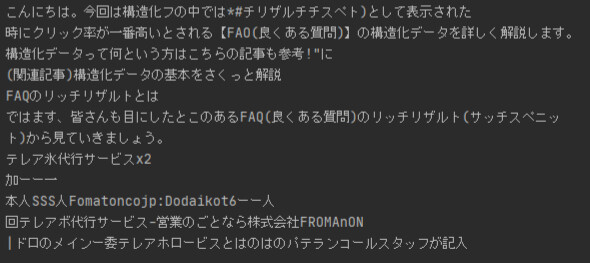
画像下部の辺りは認字出来ていませんが、本文の中はまあまあのできです。
まとめ
いかがでしたでしょうか?今回はpythonで「Tesseract」と「pyocr」を使用し画像からテキストを抽出してみました。用途によってもとめる精度は変わってくると思いますが、おおむね満足の良く結果となりました。読み込んだ画像を色などをしょりすることによって、さらに精度を高めることも出来るので、一度試してみてください。
業務支援ツールの製作を致します

株式会社FROMATIONではお客様の用途に合わせたオリジナルの業務支援(自動化)ツールを製作しております。
【毎日の10分を1秒に】
をコンセプトに、お客様の用途に特化したピンポイントな自動化ツールをご提供致します。「大手のRPAソフトを導入するまでもない日常ちょっとした手間」「毎日のルーチンワーク」など、簡単なツールで驚くほど業務が改善する場合もあります。
【毎日こんな作業で困ってるんだけど】
【こんなツール作れないかな】
など企業様も個人様もお気軽にお問い合わせください。
出来ることの一例
- webからのデータ収集
- Excelと連携したデータ処理
- メールの受信と自動返信
- データの自動アップロード
- 画像や音声データの編集・変換処
- 各種SNSの自動処理
上記以外にも出来ることは多数ありますので、お気軽にお問合せ下さい。